📚 Qlik Sense Kurs – Artikel 28 von 28
← Vorheriger Artikel: Deployment
🎉 Das ist der letzte Artikel des Kurses!
Was ist Data Governance? Etablieren von Enterprise-Standards für Naming, Modeling, Dokumentation und Code-Quality – für konsistente, wartbare und skalierbare Qlik-Lösungen im ganzen Team!
Was kannst Du über Data Governance & Standards in diesem Artikel lernen?
Nach diesem Guide kannst Du:
- Naming Conventions für Tables, Fields und Variables definieren
- Modeling Standards etablieren
- Code Review Prozess aufsetzen
Wie funktioniert das Prinzip «Consistency at Scale» in der Datenverwaltung?
Das Problem: 5 Entwickler, 5 verschiedene Stile – niemand versteht den Code der anderen, Fehler häufen sich, Wartung unmöglich!
Die Lösung: Klare Standards – einheitlicher Code, einfache Wartung, skalierbare Teams!
Was sind die 4 Säulen der Governance in Data Governance & Standards?
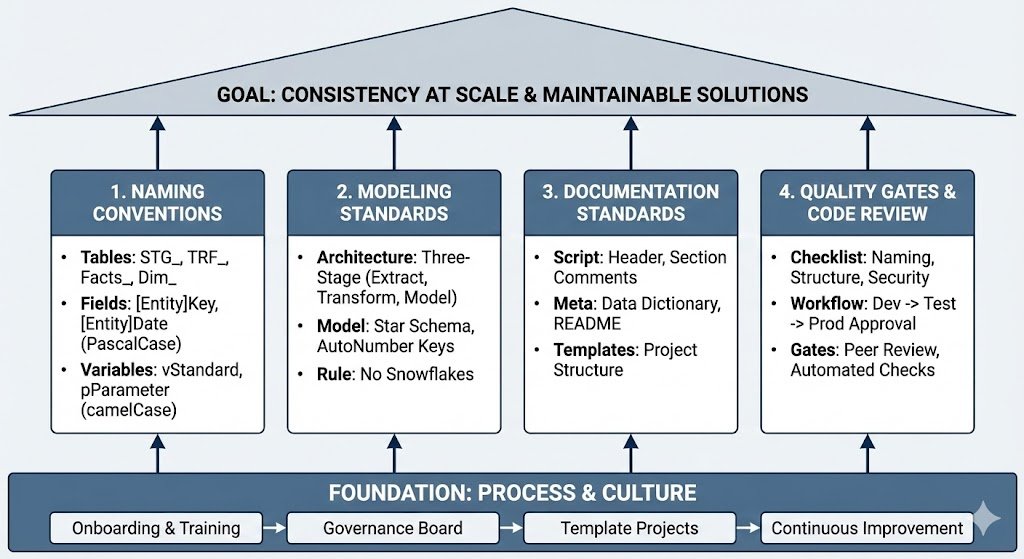
| Säule | Was? | Warum? |
|---|---|---|
| Naming Standards | Konsistente Namen für Tables, Fields, Variables | Sofort verstehen was ist was |
| Modeling Standards | Star Schema, Key-Design, Layer-Architektur | Performance, Wartbarkeit |
| Documentation | Code Comments, README, Data Dictionary | Onboarding, Knowledge Transfer |
| Quality Gates | Code Review, Testing, Approval Process | Fehler vermeiden, Qualität sichern |
Wie lauten die Namenskonventionen für Data Governance & Standards?
Wie sollte man Table Naming im Kontext von Data Governance & Standards handhaben?
| Prefix | Verwendung | Beispiele |
|---|---|---|
STG_ |
Staging Layer (Raw Extract) | STG_Sales, STG_Customers |
TRF_ |
Transform Layer (Business Logic) | TRF_Sales, TRF_Products |
Facts_ |
Fact Tables (Model Layer) | Facts_Sales, Facts_Orders |
Dim_ |
Dimension Tables (Model Layer) | Dim_Customer, Dim_Product |
Link_ |
Link Tables (Many-to-Many) | Link_CustomerProduct |
TEMP_ |
Temporäre Tables (werden gedropped) | TEMP_Join, TEMP_Calculation |
Wie benenne ich Felder im Kontext von Data Governance & Standards?
| Pattern | Konvention | Beispiele |
|---|---|---|
| Keys | [Entity]Key oder [Entity]ID | CustomerKey, OrderID, ProductKey |
| Dates | [Entity]Date | OrderDate, ShipDate, InvoiceDate |
| Amounts | [Metric]Amount | SalesAmount, DiscountAmount |
| Flags | Is[Condition] | IsCurrentYear, IsHighValue |
| Quality Flags | DQ_[Issue] | DQ_MissingEmail, DQ_InvalidAmount |
Wichtig: PascalCase (CustomerID), NICHT snake_case (customer_id) oder camelCase (customerId)!
Wie benenne ich Variablen in Data Governance & Standards?
| Prefix | Verwendung | Beispiele |
|---|---|---|
v |
Standard Variables | vDataPath, vCurrentYear |
p |
Parameter (in Subroutines) | pTableName, pPath |
tmp |
Temporäre Variables | tmpCounter, tmpResult |
Was ist das Standards-Dokument Template für Data Governance & Standards?
//============================================
// NAMING CONVENTIONS
// Company: Acme Corp
// Version: 1.2
// Last Updated: 2025-01-10
//============================================
// TABLES
// Staging: STG_[Entity] (STG_Sales)
// Transform: TRF_[Entity] (TRF_Customer)
// Facts: Facts_[Entity] (Facts_Sales)
// Dimensions: Dim_[Entity] (Dim_Product)
// Link: Link_[Entity1][Entity2]
// Temp: TEMP_[Purpose] (TEMP_Join)
// FIELDS
// Keys: [Entity]Key (CustomerKey)
// IDs: [Entity]ID (OrderID)
// Dates: [Entity]Date (OrderDate)
// Amounts: [Metric]Amount (SalesAmount)
// Flags: Is[Condition] (IsCurrentYear)
// Quality: DQ_[Issue] (DQ_Missing)
// VARIABLES
// Standard: v[Purpose] (vDataPath)
// Parameters: p[Name] (pTableName)
// Temporary: tmp[Name] (tmpCounter)
// CASE
// Tables: PascalCase (Facts_Sales)
// Fields: PascalCase (CustomerID)
// Variables: camelCase (vDataPath)
Welche Modellierungsstandards gibt es im Bereich Data Governance?
Was ist die Standardarchitektur: Three-Stage?
//============================================
// STANDARD ARCHITECTURE
//============================================
// LAYER 1: STAGING
// Purpose: Raw extract, 1:1 from source
// Naming: STG_[Entity]
// QVD: Store to QVD/Staging/
// LAYER 2: TRANSFORM
// Purpose: Business logic, cleansing, enrichment
// Naming: TRF_[Entity]
// QVD: Store to QVD/Transform/
// LAYER 3: MODEL
// Purpose: Star schema, optimized for performance
// Naming: Facts_[Entity], Dim_[Entity]
// QVD: No QVD storage (load to memory)
Was ist der Star Schema Standard in Data Governance & Standards?
//============================================
// STANDARD DATA MODEL: Star Schema
//============================================
// ✓ DO: Central Fact, flat Dimensions
Facts_Sales:
LOAD
OrderKey, // Surrogate Key
CustomerKey, // FK to Dim_Customer
ProductKey, // FK to Dim_Product
OrderDate, // FK to Calendar
SalesAmount, // Measure
Quantity // Measure
FROM [QVDTransformTRF_Sales.qvd] (qvd);
Dim_Customer:
LOAD
CustomerKey, // PK
CustomerID, // Business Key
CustomerName,
Country,
Region,
Segment // All attributes in ONE table
FROM [QVDTransformTRF_Customer.qvd] (qvd);
// ✗ DON'T: Snowflake (Region in separate table)
// → Degrades performance, complicates model
Was sind die wichtigsten Designstandards für Data Governance?
//============================================
// KEY DESIGN STANDARD
//============================================
// ✓ DO: AutoNumber in Transform Layer
TRF_Customer:
LOAD
AutoNumber(CustomerID, 'Customer') as CustomerKey,
CustomerID as CustomerID_Original, // Keep for debugging
CustomerName,
Country
FROM [QVDSTG_Customer.qvd] (qvd);
// ✓ DO: Same context across tables
TRF_Sales:
LOAD
AutoNumber(OrderID, 'Order') as OrderKey,
AutoNumber(CustomerID, 'Customer') as CustomerKey, // Same context!
SalesAmount
FROM [QVDSTG_Sales.qvd] (qvd);
// ✗ DON'T: Different contexts for same entity
AutoNumber(CustomerID, 'Cust') // ✗ Wrong
AutoNumber(CustomerID, 'Customer') // ✓ Correct
Was sind die Dokumentationsstandards für Data Governance & Standards?
Was ist eine Script Header Template im Kontext von Data Governance & Standards?
//============================================
// APPLICATION: Sales Analytics
// AUTHOR: John Doe (john.doe@company.com)
// CREATED: 2025-01-10
// LAST MODIFIED: 2025-01-15
// VERSION: 1.2.0
//============================================
// PURPOSE:
// Load and transform sales data from multiple
// sources, apply business rules, build star
// schema for analytics dashboard.
//============================================
// DATA SOURCES:
// - SQL Server: SalesDB (daily incremental)
// - Excel: Products.xlsx (weekly full)
// - REST API: Customers (hourly delta)
//============================================
// CHANGE LOG:
// 2025-01-15: Added customer segmentation (v1.2.0)
// 2025-01-12: Fixed date parsing bug (v1.1.1)
// 2025-01-10: Initial version (v1.0.0)
//============================================
Was sind die Section Comments im Bereich Data Governance & Standards?
//============================================
// SECTION 1: CONFIGURATION
//============================================
$(Must_Include=lib://Scripts/01_Config.qvs)
//============================================
// SECTION 2: STAGING LAYER
//============================================
//--------------------------------------------
// 2.1 Load Sales Data
//--------------------------------------------
STG_Sales:
LOAD
OrderID,
CustomerID,
OrderDate,
Amount
FROM [SourceSales.csv]
(txt, codepage is 1252, embedded labels);
STORE STG_Sales INTO [QVDStagingSTG_Sales.qvd] (qvd);
DROP TABLE STG_Sales;
TRACE Staging: Sales loaded - & NoOfRows('STG_Sales') & ' rows';
//--------------------------------------------
// 2.2 Load Customer Data
//--------------------------------------------
// ... etc
Was ist ein Data Dictionary?
//============================================
// DATA DICTIONARY
//============================================
DataDictionary:
LOAD * INLINE [
TableName, FieldName, DataType, Description, BusinessOwner
Facts_Sales, OrderKey, Integer, Surrogate key for order, IT
Facts_Sales, SalesAmount, Numeric, Net sales excluding tax, Finance
Facts_Sales, Quantity, Integer, Number of items sold, Sales
Dim_Customer, CustomerKey, Integer, Surrogate key for customer, IT
Dim_Customer, CustomerName, String, Full name of customer, Sales
Dim_Customer, Country, String, Customer country code (ISO), Sales
Dim_Product, ProductKey, Integer, Surrogate key for product, IT
Dim_Product, ProductName, String, Full product name, Product
Dim_Product, Category, String, Product category, Product
];
STORE DataDictionary INTO [lib://QVD/Meta/DataDictionary.qvd] (qvd);
Was sind Quality Gates & Code Review im Kontext von Data Governance & Standards?
Was sind die Punkte in der Code Review Checklist?
✓ Naming & Structure:
- [ ] Tables folgen Naming Convention (STG_, TRF_, Facts_, Dim_)
- [ ] Fields folgen Naming Convention (PascalCase)
- [ ] Variables haben Präfix (v, p, tmp)
- [ ] Three-Stage Architecture eingehalten
✓ Code Quality:
- [ ] Header mit Autor, Datum, Purpose vorhanden
- [ ] Section Comments klar strukturiert
- [ ] Komplexe Logik kommentiert
- [ ] Keine toten Code-Reste (auskommentiert)
✓ Data Quality:
- [ ] Quality Checks implementiert
- [ ] Error Handling vorhanden
- [ ] Logging aktiviert
- [ ] Validation vor Store
✓ Performance:
- [ ] Optimized QVD Loads genutzt
- [ ] AutoNumber für Keys
- [ ] WHERE EXISTS() für Dimensions
- [ ] Keine Synthetic Keys
✓ Security:
- [ ] Keine Credentials im Code
- [ ] Section Access dokumentiert (falls verwendet)
- [ ] Sensitive Daten maskiert
Wie funktioniert der Approval Workflow in Data Governance & Standards?
1. Developer creates Feature Branch
└─ feature/new-dimension
2. Developer implements & self-tests
└─ Tests in DEV environment
3. Pull Request erstellen
└─ In Git/Azure DevOps/Bitbucket
4. Code Review durch Senior Dev
└─ Checklist durchgehen
└─ Kommentare zu Verbesserungen
5. Developer behebt Review-Comments
└─ Push updates to Feature Branch
6. Approval durch Reviewer
└─ Merge zu dev-Branch
7. Deployment zu TEST
└─ QA Testing
8. Sign-Off durch Business
└─ UAT erfolgreich
9. Deployment zu PROD
└─ Nach Approval durch Tech Lead
Was sind Template Projects im Zusammenhang mit Data Governance & Standards?
Wie ist die Struktur des Starter Template in Data Governance & Standards?
qlik-template-project/
├── README.md
├── CHANGELOG.md
├── .gitignore
├── scripts/
│ ├── 00_Environment.qvs.template
│ ├── 01_Config_DEV.qvs
│ ├── 01_Config_TEST.qvs
│ ├── 01_Config_PROD.qvs
│ ├── 02_Functions.qvs
│ ├── 03_Subroutines.qvs
│ ├── 10_Staging.qvs
│ ├── 20_Transform.qvs
│ ├── 30_Model.qvs
│ └── 99_Validation.qvs
├── docs/
│ ├── Architecture.md
│ ├── Deployment.md
│ └── Naming_Conventions.md
└── tests/
└── validation_tests.qvs
Was ist das README Template für Data Governance & Standards?
# [Project Name]
## Overview
[Brief description of the application]
## Architecture
- Three-Stage Architecture (Staging/Transform/Model)
- Star Schema with [N] Facts and [M] Dimensions
## Data Sources
- [Source 1]: [Description] ([Update Frequency])
- [Source 2]: [Description] ([Update Frequency])
## Setup
1. Clone repository
2. Create `scripts/00_Environment.qvs` with: `SET vEnvironment = 'DEV';`
3. Configure data connections in QMC
4. Run initial full load
## Deployment
See [docs/Deployment.md](docs/Deployment.md)
## Contacts
- Owner: [Name] ([Email])
- Team: [Team Name]
## Version
Current: [Version Number]
Was ist ein Governance Board im Kontext von Data Governance & Standards?
Was sind die Rollen & Verantwortlichkeiten in Data Governance & Standards?
| Rolle | Verantwortlichkeiten |
|---|---|
| Data Governance Lead | Standards definieren, Reviews koordinieren, Escalations |
| Senior Developers | Code Reviews, Mentoring, Architecture Decisions |
| Developers | Standards befolgen, Peer Reviews, Dokumentation |
| Business Analysts | Requirements, UAT, Business Rules validieren |
Was steht auf der Agenda für das Governance Meeting?
Monatliches Governance Meeting:
- Review neuer Standards/Updates (15 Min)
- Diskussion offener Architektur-Fragen (20 Min)
- Lessons Learned aus letztem Monat (15 Min)
- Training-Bedarf identifizieren (10 Min)
Wie onboarding ich neue Entwickler in Data Governance & Standards?
Was ist die Onboarding Checklist für Data Governance & Standards?
Woche 1: Basics
- [ ] Accounts & Zugriffe eingerichtet
- [ ] Naming Conventions Dokument lesen
- [ ] Template Project durchgehen
- [ ] Einfache Bugfix-Task (mit Mentor Review)
Woche 2-3: Standards
- [ ] Three-Stage Architecture verstehen
- [ ] Code Review Checklist durchgehen
- [ ] Feature-Branch erstellen und mergen
- [ ] Erste kleine Feature implementieren
Woche 4: Selbstständig
- [ ] Mittelgroße Feature eigenständig umsetzen
- [ ] Code Review für andere durchführen
- [ ] Deployment-Prozess durchgeführt
Was sind die Best Practices für Data Governance & Standards?
✓ Standards etablieren:
- [ ] Naming Conventions dokumentiert
- [ ] Modeling Standards definiert
- [ ] Documentation Requirements festgelegt
- [ ] Template Projects erstellt
✓ Prozesse implementieren:
- [ ] Code Review obligatorisch
- [ ] Approval Workflow etabliert
- [ ] Governance Board gebildet
- [ ] Regelmäßige Reviews geplant
✓ Team enablen:
- [ ] Onboarding-Prozess definiert
- [ ] Training-Material verfügbar
- [ ] Mentoring-System etabliert
- [ ] Living Documentation
Wie kann ich bei Data Governance & Standards Troubleshooting durchführen?
⚠️ Problem: Team hält sich nicht an Standards
Ursachen:
- Standards nicht klar kommuniziert
- Keine Consequences bei Nicht-Einhaltung
- Standards zu komplex/unrealistisch
Lösungen:
- Training für alle Team-Members
- Code Reviews strikt durchführen
- Automated Checks wo möglich
- Positive Reinforcement (Lob für guten Code)
- Standards regelmäßig reviewen und anpassen
⚠️ Problem: Code Reviews verzögern Deployment
Lösungen:
- Dedicated Review-Time einplanen
- Review SLA definieren (z.B. 24h Response)
- Pair Programming für kritische Features
- Automated Checks reduzieren manuellen Aufwand
- Multiple Reviewers trainieren
⚠️ Problem: Dokumentation wird nicht gepflegt
Lösungen:
- Dokumentation als Teil der Definition of Done
- Templates vereinfachen Dokumentation
- Code Review prüft auch Dokumentation
- Dedizierte Zeit für Documentation Sprints
- Tools wie Confluence/Wiki nutzen
Welche Erfolgskennzahlen gibt es im Bereich Data Governance & Standards?
Messe Erfolg der Governance-Initiative:
| Metrik | Ziel |
|---|---|
| Code Review Coverage | 100% aller Changes |
| Standards Compliance | >95% bei Reviews |
| Onboarding Time | <4 Wochen bis produktiv |
| Production Incidents | Trend abnehmend |
| Developer Satisfaction | >4/5 in Survey |
Wie schließt man den Kurs in Data Governance & Standards ab?
Wie feiere ich Erfolge in Data Governance & Standards?
Du hast alle 28 Artikel des Qlik Sense Kurses abgeschlossen!
Du kannst jetzt:
- ✓ Daten aus beliebigen Quellen laden und transformieren
- ✓ Optimale Data Models (Star Schema) bauen
- ✓ Performance-optimierte Apps entwickeln
- ✓ Enterprise-Architecture (Three-Stage) implementieren
- ✓ Professional Deployment durchführen
- ✓ Data Governance etablieren
Was nun?
1. Practice, Practice, Practice:
- Baue eigene Projekte mit echten Daten
- Setze alle Patterns aus dem Kurs um
- Experimentiere und optimiere
2. Community:
- Qlik Community (community.qlik.com)
- Qlik Help (help.qlik.com)
- LinkedIn Groups
3. Weiterentwicklung:
- Qlik Sense APIs & Extensions
- Advanced Analytics (R/Python Integration)
- NPrinting für Reporting
- GeoAnalytics
Was ist der Kurs-Überblick zu Data Governance & Standards?
Das waren alle 28 Artikel:
- Basics (1-7): Daten laden, Transformieren, QVD
- Modeling (8-14): Star Schema, Dimensions, Historisierung
- Advanced (15-20): Calendar, Expressions, Quality
- Architecture (21-26): Monitoring, Three-Stage, Performance
- Enterprise (27-28): Deployment, Governance
Viel Erfolg mit Qlik Sense! 🚀
Slug: qlik-data-governance
Keywords: Qlik Data Governance, Qlik Naming Conventions, Qlik Standards, Code Review Qlik, Qlik Best Practices, Modeling Standards Qlik, Documentation Qlik, Template Projects Qlik